Fractals are some of the most mesmerizing visuals in computer graphics, but rendering them in 3D space requires
special techniques beyond standard polygonal rendering. This article will take you into the world of ray marching,
where we’ll use distance fields, lighting, and soft shadows to render a Mandelbulb fractal — one of the most famous 3D
fractals.
By the end of this post, you’ll understand:
The basics of ray marching and signed distance functions (SDFs).
How to render 3D objects without polygons.
How to implement Phong shading for realistic lighting.
How to compute soft shadows for better depth.
How to animate a rotating Mandelbulb fractal.
This article will build on the knowledge that we established in the Basics of Shader Programming
article that we put together earlier. If you haven’t read through that one, it’ll be worth taking a look at.
What is Ray Marching?
Ray marching is a distance-based rendering technique that is closely related to ray tracing.
However, instead of tracing rays until they hit exact geometry (like in traditional ray tracing), ray marching steps
along the ray incrementally using distance fields.
Each pixel on the screen sends out a ray into 3D space. We then march forward along the ray, using a signed
distance function (SDF) to tell us how far we are from the nearest object. This lets us render smooth implicit
surfaces like fractals and organic shapes.
Our first SDF
The simplest 3D object we can render using ray marching is a sphere. We define its shape using a
signed distance function (SDF):
// Sphere Signed Distance Function (SDF)floatsdfSphere(vec3p,floatr){returnlength(p)-r;}
The sdfSphere() function returns the shortest distance from any point in space to the sphere’s surface.
We can now step along that ray until we reach the sphere. We do this by integrating our sfpSphere() function into our
mainImage() function:
voidmainImage(outvec4fragColor,invec2fragCoord){vec2uv=(fragCoord-0.5*iResolution.xy)/iResolution.y;// Camera setupvec3rayOrigin=vec3(0,0,-3);vec3rayDir=normalize(vec3(uv,1));floattotalDistance=0.0;constintmaxSteps=100;constfloatminDist=0.001;constfloatmaxDist=20.0;for(inti=0;i<maxSteps;i++){vec3pos=rayOrigin+rayDir*totalDistance;floatdist=sdfSphere(pos,1.0);if(dist<minDist)break;if(totalDistance>maxDist)break;totalDistance+=dist;}vec3col=(totalDistance<maxDist)?vec3(1.0):vec3(0.2,0.3,0.4);fragColor=vec4(col,1.0);}
First of all here, we convert the co-ordinate that we’re processing into screen co-ordinates:
We now iterate (march) down the ray to a maximum of maxSteps (currently set to 100) to determine if the ray
intersects with our sphere (via sdfSphere).
Finally, we render the colour of our sphere if the distance is within tolerance; otherwise we consider this part of
the background:
In order to make this sphere look a little more 3D, we can light it. In order to light any object, we need to be able
to compute surface normals. We do that via a function like this:
vec3getNormal(vec3p){vec2e=vec2(0.001,0.0);// Small offset for numerical differentiationreturnnormalize(vec3(sdfSphere(p+e.xyy,1.0)-sdfSphere(p-e.xyy,1.0),sdfSphere(p+e.yxy,1.0)-sdfSphere(p-e.yxy,1.0),sdfSphere(p+e.yyx,1.0)-sdfSphere(p-e.yyx,1.0)));}
We make decisions about the actual colour via a lighting function. This lighting function is informed by the surface
normals that it computes:
vec3lighting(vec3p){vec3lightPos=vec3(2.0,2.0,-2.0);// Light source positionvec3normal=getNormal(p);// Compute the normal at point 'p'vec3lightDir=normalize(lightPos-p);// Direction to lightfloatdiff=max(dot(normal,lightDir),0.0);// Diffuse lightingreturnvec3(diff);// Return grayscale lighting effect}
We can now integrate this back into our scene in the mainImage function. Rather than just making a static colour
return when we establish a hit point, we start to execute the lighting function towards the end of the function:
voidmainImage(outvec4fragColor,invec2fragCoord){vec2uv=(fragCoord-0.5*iResolution.xy)/iResolution.y;// Camera setupvec3rayOrigin=vec3(0,0,-3);// Camera positioned at (0,0,-3)vec3rayDir=normalize(vec3(uv,1));// Forward-facing ray// Ray marching parametersfloattotalDistance=0.0;constintmaxSteps=100;constfloatminDist=0.001;constfloatmaxDist=20.0;vec3hitPoint;// Ray marching loopfor(inti=0;i<maxSteps;i++){hitPoint=rayOrigin+rayDir*totalDistance;floatdist=sdfSphere(hitPoint,1.0);// Distance to the sphereif(dist<minDist)break;// If we are close enough to the surface, stopif(totalDistance>maxDist)break;// If we exceed max distance, stoptotalDistance+=dist;}// If we hit something, apply shading; otherwise, keep background colorvec3col=(totalDistance<maxDist)?lighting(hitPoint):vec3(0.2,0.3,0.4);fragColor=vec4(col,1.0);}
You should see something similar to this:
Mandelbulbs
We can now upgrade our rendering to use something a little more complex then our sphere.
SDF
The Mandelbulb is a 3D fractal inspired by the 2D Mandelbrot Set. Instead of working in 2D complex numbers, it uses
spherical coordinates in 3D space.
The core formula: \(z→zn+c\) is extended to 3D using spherical math.
Instead of a sphere SDF, we’ll use an iterative function to compute distances to the fractal surface.
This function iterates over complex numbers in 3D space to compute the Mandelbulb structure.
Raymarching the Mandelbulb
Now, we can take a look at what this produces. We use our newly created SDF to get our hit point. We’ll use this
distance value as well to establish different colours.
voidmainImage(outvec4fragColor,invec2fragCoord){vec2uv=(fragCoord-0.5*iResolution.xy)/iResolution.y;// Camera setupvec3rayOrigin=vec3(0,0,-4);vec3rayDir=normalize(vec3(uv,1));// Ray marching parametersfloattotalDistance=0.0;constintmaxSteps=100;constfloatminDist=0.001;constfloatmaxDist=10.0;vec3hitPoint;// Ray marching loopfor(inti=0;i<maxSteps;i++){hitPoint=rayOrigin+rayDir*totalDistance;floatdist=mandelbulbSDF(hitPoint);// Fractal distance functionif(dist<minDist)break;if(totalDistance>maxDist)break;totalDistance+=dist;}// Color based on distance (simple shading)vec3col=(totalDistance<maxDist)?vec3(1.0-totalDistance*0.1):vec3(0.1,0.1,0.2);fragColor=vec4(col,1.0);}
You should see something similar to this:
Rotation
We can’t see much with how this object is oriented. By adding some basic animation, we can start to look at the complexities
of how this object is put together. We use the global iTime variable here to establish movement:
voidmainImage(outvec4fragColor,invec2fragCoord){vec2uv=(fragCoord-0.5*iResolution.xy)/iResolution.y;// Rotate camera around the fractal using iTimefloatangle=iTime*0.5;// Adjust speed of rotationvec3rayOrigin=vec3(3.0*cos(angle),0.0,3.0*sin(angle));// Circular pathvec3target=vec3(0.0,0.0,0.0);// Looking at the fractalvec3forward=normalize(target-rayOrigin);vec3right=normalize(cross(vec3(0,1,0),forward));vec3up=cross(forward,right);vec3rayDir=normalize(forward+uv.x*right+uv.y*up);// Ray marching parametersfloattotalDistance=0.0;constintmaxSteps=100;constfloatminDist=0.001;constfloatmaxDist=10.0;vec3hitPoint;// Ray marching loopfor(inti=0;i<maxSteps;i++){hitPoint=rayOrigin+rayDir*totalDistance;floatdist=mandelbulbSDF(hitPoint);// Fractal distance functionif(dist<minDist)break;if(totalDistance>maxDist)break;totalDistance+=dist;}// Color based on distance (simple shading)vec3col=(totalDistance<maxDist)?vec3(1.0-totalDistance*0.1):vec3(0.1,0.1,0.2);fragColor=vec4(col,1.0);}
You should see something similar to this:
Lights
In order to make our fractal look 3D, we need to be able to compute our surface normals. We’ll be using the
mandelbulbSDF function above to accomplish this:
To make the fractal look more realistic, we’ll implement soft shadows. This will really enhance how this object looks.
// Soft Shadows (traces a secondary ray to detect occlusion)floatsoftShadow(vec3ro,vec3rd){floatres=1.0;floatt=0.02;// Small starting stepfor(inti=0;i<24;i++){floatd=mandelbulbSDF(ro+rd*t);if(d<0.001)return0.0;// Fully in shadowres=min(res,10.0*d/t);// Soft transitiont+=d;}returnres;}
Pulling it all together
We can now pull all of these enhancements together with our main image function:
voidmainImage(outvec4fragColor,invec2fragCoord){vec2uv=(fragCoord-0.5*iResolution.xy)/iResolution.y;// Rotating Camerafloatangle=iTime*0.5;vec3rayOrigin=vec3(3.0*cos(angle),0.0,3.0*sin(angle));vec3target=vec3(0.0);vec3forward=normalize(target-rayOrigin);vec3right=normalize(cross(vec3(0,1,0),forward));vec3up=cross(forward,right);vec3rayDir=normalize(forward+uv.x*right+uv.y*up);// Ray marchingfloattotalDistance=0.0;constintmaxSteps=100;constfloatminDist=0.001;constfloatmaxDist=10.0;vec3hitPoint;for(inti=0;i<maxSteps;i++){hitPoint=rayOrigin+rayDir*totalDistance;floatdist=mandelbulbSDF(hitPoint);if(dist<minDist)break;if(totalDistance>maxDist)break;totalDistance+=dist;}// Compute lighting only if we hit the fractalvec3color;if(totalDistance<maxDist){vec3viewDir=normalize(rayOrigin-hitPoint);vec3baseLight=phongLighting(hitPoint,viewDir);floatshadow=softShadow(hitPoint,normalize(vec3(2.0,2.0,-2.0)));color=baseLight*shadow;// Apply shadows}else{color=vec3(0.1,0.1,0.2);// Background color}fragColor=vec4(color,1.0);}
Finally, you should see something similar to this:
Shaders are one of the most powerful tools in modern computer graphics, allowing real-time effects, lighting, and
animation on the GPU (Graphics Processing Unit). They are used in games, simulations, and rendering engines
to control how pixels and geometry appear on screen.
In this article, we’ll break down:
What shaders are and why they matter
How to write your first shader
Understanding screen coordinates
Animating a shader
This guide assumes zero prior knowledge of shaders and will explain each line of code step by step.
All of the code here can be run using Shadertoy. You won’t need to install any dependencies,
but you will need a GPU-capable computer!
What is a Shader?
A shader is a small program that runs on the GPU. Unlike regular CPU code, shaders are executed in parallel for
every pixel or vertex on the screen.
Types of Shaders
Vertex Shader – Moves and transforms individual points in 3D space.
Fragment Shader (Pixel Shader) – Determines the final color of each pixel.
For now, we’ll focus on fragment shaders since they control how things look.
Your First Shader
Let’s start with the simplest shader possible: a solid color fill.
Seeing Red!
voidmainImage(outvec4fragColor,invec2fragCoord){fragColor=vec4(1.0,0.0,0.0,1.0);// Solid red color}
Breaking this code down:
void mainImage(...) → This function runs for every pixel on the screen.
fragColor → The output color of the pixel.
vec4(1.0, 0.0, 0.0, 1.0) → This defines an RGBA color:
1.0, 0.0, 0.0 → Red
1.0 → Fully opaque (no transparency)
Try This: Change the color values:
vec4(0.0, 1.0, 0.0, 1.0); → Green
vec4(0.0, 0.0, 1.0, 1.0); → Blue
vec4(1.0, 1.0, 0.0, 1.0); → Yellow
Mapping Colors to Screen Position
Instead of filling the screen with a single color, let’s map colors to pixel positions.
A Gradient Shader
voidmainImage(outvec4fragColor,invec2fragCoord){vec2uv=fragCoord/iResolution.xy;// Normalize coordinates (0 to 1)fragColor=vec4(uv.x,uv.y,0.5,1.0);}
Breaking this code down:
fragCoord / iResolution.xy → Converts pixel coordinates into a 0 → 1 range.
uv.x → Controls red (left to right gradient).
uv.y → Controls green (bottom to top gradient).
0.5 → Keeps blue constant.
This creates a smooth gradient across the screen!
Try This: Swap uv.x and uv.y to see different patterns.
Animation
Shaders can react to time using iTime. This lets us create dynamic effects.
sin(uv.x * 10.0 + iTime) → Creates waves that move over time.
The whole screen pulses from black to white dynamically.
Try This: Change 10.0 to 20.0 or 5.0 to make waves tighter or wider.
Wrapping up
Here have been some very simple shader programs to get started with. In future articles, we’ll build on this knowledge
to build more exciting graphics applications.
Radio signals surround us every day—whether it’s FM radio in your car, WiFi on your laptop, or Bluetooth connecting
your phone to wireless headphones. These signals are all based on the same fundamental principles: frequency,
modulation, and bandwidth.
In today’s article, I want to go through some of the fundamentals:
How do radio signals travel through the air?
What is the difference between AM and FM?
How can multiple signals exist without interfering?
What is digital modulation (FSK & PSK), and why does it matter?
How can we capture and transmit signals using HackRF?
By the end of this article, we should be running some experiments with our own software defined radio devices.
Getting Setup
Before getting started in this next section, you’ll want to make sure that you have some specific software installed
on your computer, as well as a software defined radio device.
I’m using a HackRF One as my device of choice as it integrates with all of
the software that I use.
Make sure you have the following packages installed:
hackrf
gqrx
gnuradio
sudo pacman -S hackrf gqrx gnuradio
Create yourself a new python project and virtual environment, and install the libraries that will wrap some of these
tools to give you an easy to use programming environment for your software defined radio.
The output of some of these examples are graphs, so we use matplotlib to save them to look at later.
Be Responsible!
A note before we get going - you will be installing software that will allow you to transmit signals that could
potentially be dangerous and against the law, so before transmitting:
Know the laws – Unlicensed transmission can interfere with emergency services.
Use ISM Bands – 433 MHz, 915 MHz, 2.4 GHz are allowed for low-power use.
Start in Receive Mode – Learning to capture first avoids accidental interference.
Basics of Radio Waves
What is a Radio Signal?
A radio signal is a type of electromagnetic wave that carries information through the air. These waves travel at the
speed of light and can carry audio, video, or digital data.
Radio waves are defined by:
Frequency (Hz) – How fast the wave oscillates.
Wavelength (m) – The distance between peaks.
Amplitude (A) – The height of the wave (strength of the signal).
A high-frequency signal oscillates faster and has a shorter wavelength. A low-frequency signal oscillates slower and
has a longer wavelength.
Since radio waves travel at the speed of light, their wavelength (\(\lambda\)) can be calculated using:
\[\lambda = \frac{c}{f}\]
Where:
\(\lambda\) = Wavelength in meters
\(c\) = Speed of light ~(\(3.0 \times 10^8\) m/s)
\(f\) = Frequency in Hz
What is Frequency?
Frequency is measured in Hertz (Hz), meaning cycles per second. You may have heard of kilohertz, megahertz, and
gigahertz. These are all common frequency units:
Unit
Hertz
1 kHz (kilohertz)
1,000 Hz
1 MHz (megahertz)
1,000,000 Hz
1 GHz (gigahertz)
1,000,000,000 Hz
Every device that uses radio has a specific frequency range. For example:
AM Radio: 530 kHz – 1.7 MHz
FM Radio: 88 MHz – 108 MHz
WiFi (2.4 GHz Band): 2.4 GHz – 2.5 GHz
Bluetooth: 2.4 GHz
GPS Satellites: 1.2 GHz – 1.6 GHz
Each of these frequencies belongs to the radio spectrum, which is carefully divided so that signals don’t interfere
with each other.
What is Bandwidth?
Bandwidth is the amount of frequency space a signal occupies.
A narrowband signal (like AM radio) takes up less space. A wideband signal (like WiFi) takes up more space to
carry more data.
Example:
AM Radio Bandwidth: ~10 kHz per station
FM Radio Bandwidth: ~200 kHz per station
WiFi Bandwidth: 20–80 MHz (much larger, more data)
The more bandwidth a signal has, the better the quality (or more data it can carry).
How Can Multiple Signals Exist Together?
One analogy you can use is imagining a highway—each lane is a different frequency. Cars (signals) stay in their lanes and don’t interfere unless they overlap (cause interference). This is why:
FM stations are spaced apart (88.1 MHz, 88.3 MHz, etc.).
WiFi has channels (1, 6, 11) to avoid congestion.
TV channels each have a dedicated frequency band.
This method of dividing the spectrum is called Frequency Division Multiplexing (FDM).
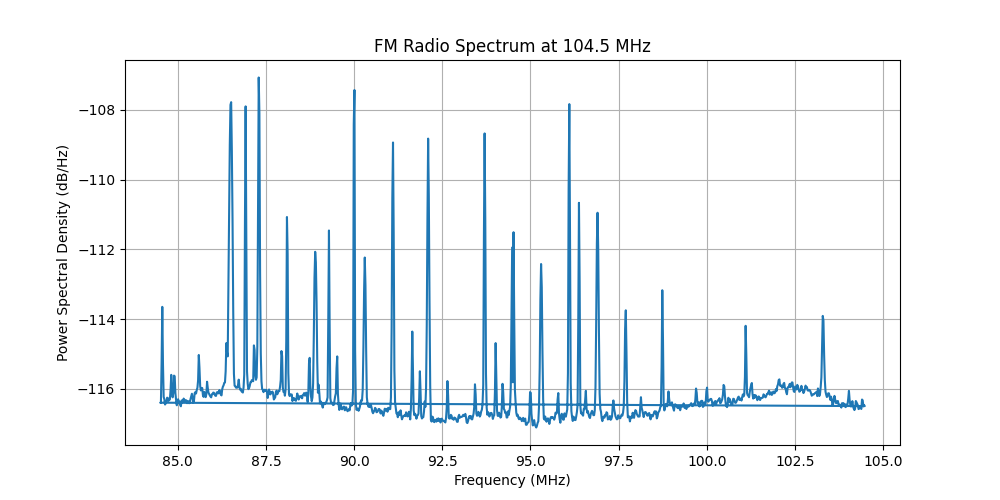
Using the following python code, we can visualise FDM in action by sweeping the FM spectrum:
# Basic FM Spectrum Capture
fromhackrfimport*importmatplotlib.pyplotaspltimportnumpyasnpfromscipy.signalimportwelchwithHackRF()ashrf:hrf.sample_rate=20e6# 20 MHz sample rate
hrf.center_freq=104.5e6# FM Radio
samples=hrf.read_samples(2e6)# Capture 2 million samples
# Compute PSD using Welch’s method (handling complex IQ data)
freqs,psd_values=welch(samples,fs=hrf.sample_rate,nperseg=1024,return_onesided=False)# Convert frequency axis to MHz
freqs_mhz=(freqs-(hrf.sample_rate/2))/1e6+(hrf.center_freq/1e6)# Plot Power Spectral Density
plt.figure(figsize=(10,5))plt.plot(freqs_mhz,10*np.log10(psd_values))# Convert power to dB
plt.xlabel('Frequency (MHz)')plt.ylabel('Power Spectral Density (dB/Hz)')plt.title(f'FM Radio Spectrum at {hrf.center_freq/1e6} MHz')plt.grid()# Save and show
plt.savefig("fm_spectrum.png")plt.show(block=True)
Running this code gave me the following resulting plot (it will be different for you depending on where you live!):
Each sharp peak that you see here represents an FM station at a unique frequency. These are the lanes.
Understanding Modulation
What is Modulation?
Radio signals don’t carry useful information by themselves. Instead, they use modulation to encode voice, music, or
data.
There are two main types of modulation:
Analog Modulation – Used for traditional radio (AM/FM).
Digital Modulation – Used for WiFi, Bluetooth, GPS, and modern systems.
AM (Amplitude Modulation)
AM works by varying the height (amplitude) of the carrier wave to encode audio.
As an example, the carrier frequency stays the same (e.g., 900 kHz), but the amplitude changes based on the sound wave.
AM is prone to static noise (because any electrical interference changes amplitude).
You can capture a sample of AM signals using the hackrf_transfer utility that was installed on your system:
This will capture AM signals at 900 kHz into a file for later analysis.
We can write some python to capture an AM signal and plot the samples so we can visualise this information.
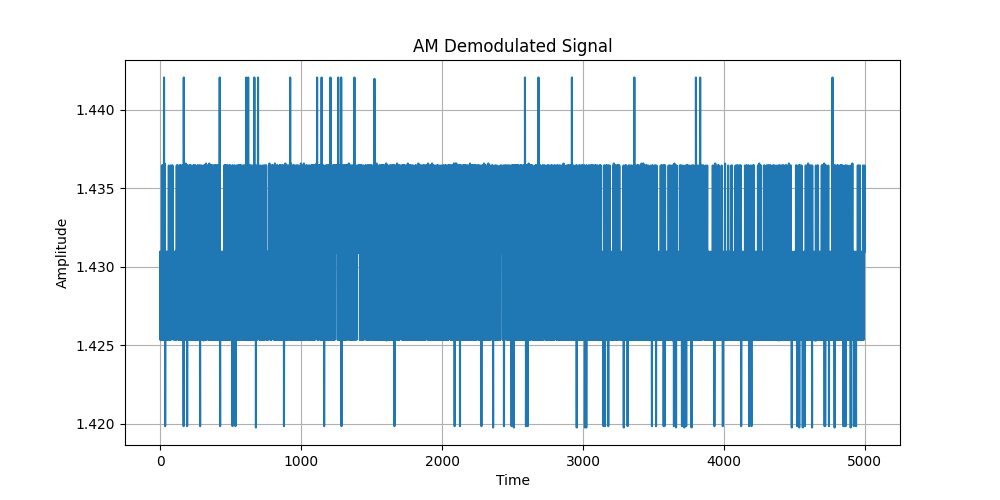
# AM Signal Demodulation
fromhackrfimport*importmatplotlib.pyplotaspltimportnumpyasnpwithHackRF()ashrf:hrf.sample_rate=10e6# 10 MHz sample rate
hrf.center_freq=693e6# 693 MHz AM station
samples=hrf.read_samples(1e6)# Capture 1M samples
# AM Demodulation - Extract Magnitude (Envelope Detection)
demodulated=np.abs(samples)# Plot Demodulated Signal
plt.figure(figsize=(10,5))plt.plot(demodulated[:5000])# Plot first 5000 samples
plt.xlabel("Time")plt.ylabel("Amplitude")plt.title("AM Demodulated Signal")plt.grid()# Save and show
plt.savefig("am_demodulated.png")plt.show(block=True)
Running this code should give you a plot of what’s happening at 693 MHz:
The plot above represents the amplitude envelope of a real AM radio transmission.
The X-axis represents time, while the Y-axis represents amplitude.
The variations in amplitude correspond to the audio signal encoded by the AM station.
FM (Frequency Modulation)
FM works by varying the frequency of the carrier wave to encode audio.
As an example, the amplitude stays constant, but the frequency changes based on the audio wave.
FM is clearer than AM because it ignores amplitude noise.
You can capture a sample of FM signals with the following:
We can write some python code to capture and demodulate an FM signal as well:
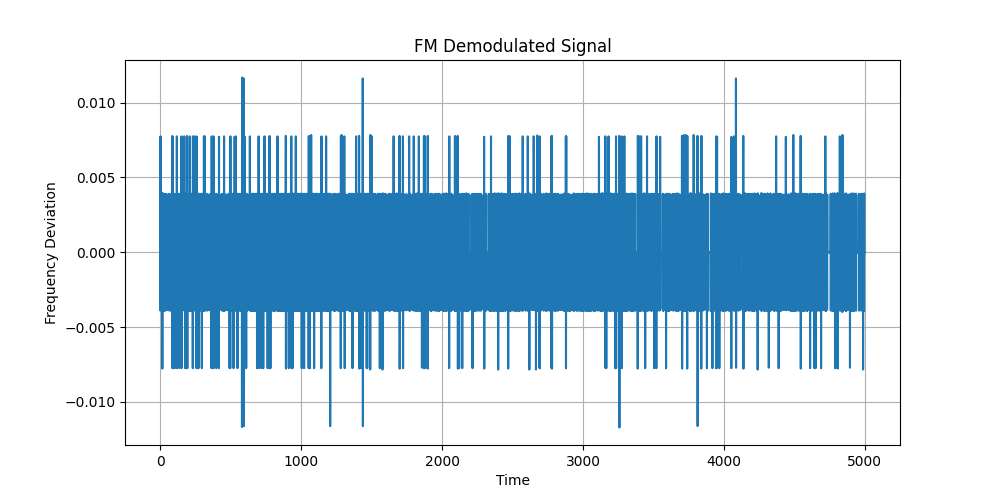
fromhackrfimport*importmatplotlib.pyplotaspltimportnumpyasnpwithHackRF()ashrf:hrf.sample_rate=2e6# 2 MHz sample rate
hrf.center_freq=104.5e6# Example FM station
samples=hrf.read_samples(1e6)# FM Demodulation - Phase Differentiation
phase=np.angle(samples)# Extract phase
fm_demodulated=np.diff(phase)# Differentiate phase
# Plot FM Demodulated Signal
plt.figure(figsize=(10,5))plt.plot(fm_demodulated[:5000])# Plot first 5000 samples
plt.xlabel("Time")plt.ylabel("Frequency Deviation")plt.title("FM Demodulated Signal")plt.grid()# Save and show
plt.savefig("fm_demodulated.png")plt.show(block=True)
If you pick a frequency that has a local radio station, you should get a strong signal like this:
Unlike AM, where the signal’s amplitude changes, FM signals encode audio by varying the frequency of the carrier wave.
The graph above shows the frequency deviation over time:
The X-axis represents time, showing how the signal changes.
The Y-axis represents frequency deviation, showing how much the carrier frequency shifts.
The spikes and variations represent audio modulation, where frequency shifts encode sound.
If your FM demodulation appears too noisy:
Try tuning to a stronger station (e.g., 100.3 MHz).
Increase the sample rate for a clearer signal.
Apply a low-pass filter to reduce noise in post-processing.
Bandwidth of a Modulated Signal
Modulated signals require bandwidth (\(B\)), and the amount depends on the modulation type.
AM
The total bandwidth required for AM signals is:
\[B = 2f_m\]
Where:
\(B\) = Bandwidth in Hz
\(f_m\) = Maximum audio modulation frequency in Hz
If an AM station transmits audio up to 5 kHz, the bandwidth is:
\[B = 2 \times 5\text{kHz} = 10\text{kHz}\]
This explains why AM radio stations typically require ~10 kHz per station.
FM
The bandwidth required for an FM signal follows Carson’s Rule:
\[B = 2 (f_d + f_m)\]
Where:
\(f_d\) = Peak frequency deviation (how much the frequency shifts)
\(f_m\) = Maximum audio frequency in Hz
For an FM station with a deviation of 75 kHz and max audio frequency of 15 kHz, the total bandwidth is:
\[B = 2 (75 + 15) = 180 \text{kHz}\]
This explains why FM radio stations require much more bandwidth (~200 kHz per station).
Digital Modulation
For digital signals, it’s important to be able to transmit binary data (1’s and 0’s). These methods of modulation are
focused on making this process much more optimal than what the analog counterparts could provide.
What is FSK (Frequency Shift Keying)?
FSK is digital FM—instead of smoothly varying frequency like FM radio, it switches between two frequencies for 0’s and
1’s. This method of modulation is used in technologies like Bluetooth, LoRa, and old-school modems.
Example:
A “0” might be transmitted as a lower frequency (e.g., 915 MHz).
A “1” might be transmitted as a higher frequency (e.g., 917 MHz).
The receiver detects these frequency changes and reconstructs the binary data.
What is PSK (Phase Shift Keying)?
PSK is digital AM—instead of changing amplitude, it shifts the phase of the wave. This method of modulation is used
in technologies like WiFi, GPS, 4G LTE, Satellites.
Example:
0° phase shift = Binary 0
180° phase shift = Binary 1
More advanced PSK (like QPSK) uses four phase shifts (0°, 90°, 180°, 270°) to send two bits per symbol (faster data transmission).
Wrapping Up
In this post, we explored the fundamentals of radio signals—what they are, how they work, and how different modulation
techniques like AM and FM allow signals to carry audio through the air.
This really is only the start of what you can get done with software defined radio. Here are some further resources to
check out:
Previously, we’ve explored WASM in rust as well as some more advanced
concepts with Pixel Buffer Rendering again from
Rust. In today’s article, we’ll go through WebAssembly from a more fundamental perspective.
WebAssembly (Wasm) is a powerful technology that enables high-performance execution in web browsers and beyond. If
you’re just getting started, this guide will walk you through writing a simple WebAssembly program from scratch,
running it in a browser using JavaScript.
What is WebAssembly?
WebAssembly is a low-level binary instruction format that runs at near-native speed. It provides a sandboxed execution
environment, making it secure and highly portable. While it was initially designed for the web, Wasm is now expanding
into cloud computing, serverless, and embedded systems.
Unlike JavaScript, Wasm allows near-native performance, making it ideal for gaming, video processing, and even AI in
the browser.
First program
Before we start, we need to make sure all of the tools are available on your system. Make sure you have
wabt installed on your system:
sudo pacman -S wabt
WAT
We’ll start by writing a WebAssembly module using the WebAssembly Text Format (WAT).
Create a file called add.wat with the following code:
This module defines a function $add that takes two 32-bit integers (i32) as parameters and returns their sum.
local.get retrieves the parameters.
i32.add performs the addition.
The function is exported as "add", making it accessible from JavaScript
wat2wasm
To convert our add.wat file into a .wasm binary, we’ll use a tool called wat2wasm from the
WebAssembly Binary Toolkit (wabt) that we installed earlier:
wat2wasm add.wat -o add.wasm
This produces a binary add.wasm file, ready for execution.
Running WebAssembly from Javascript
Now, let’s create a JavaScript file (index.js) to load and execute our Wasm module:
asyncfunctionrunWasm(){// Fetch and compile the Wasm moduleconstresponse=awaitfetch("add.wasm");constbuffer=awaitresponse.arrayBuffer();constwasmModule=awaitWebAssembly.instantiate(buffer);// Get the exported add functionconstadd=wasmModule.instance.exports.add;// Call the functionconsole.log("5 + 7 = ",add(5,7));}runWasm();
We can execute this javascript by referencing it from a html file, and running this in a browser.
In the world of computational geometry, Delaunay triangulation stands out as one of the most versatile and powerful
algorithms. Its ability to transform a scattered set of points into a structured mesh of triangles has applications
ranging from terrain modeling to wireless network optimization.
This blog explores the concept of Delaunay triangulation, the algorithms that implement it, and its real-world
applications.
What is Delaunay Triangulation?
Delaunay triangulation is a method for connecting a set of points in a plane (or higher dimensions) to form a network
of triangles. The primary property of this triangulation is that no point lies inside the circumcircle of any triangle.
This ensures the triangulation is “optimal” in the sense that it avoids skinny triangles and maximizes the smallest
angles in the mesh.
A key relationship is its duality with the Voronoi diagram: Delaunay
triangulation and Voronoi diagrams together provide complementary ways to describe the spatial relationships between
points.
Why is Delaunay Triangulation Important?
The importance of Delaunay triangulation stems from its geometric and computational properties:
Optimal Mesh Quality: By avoiding narrow angles, it produces meshes suitable for simulations, interpolation, and rendering.
Simplicity and Efficiency: It reduces computational overhead by connecting points with minimal redundant edges.
Wide Applicability: From geographic information systems (GIS) to computer graphics and engineering, Delaunay triangulation plays a foundational role.
Real-World Applications
Geographic Information Systems (GIS)
Terrain Modeling: Delaunay triangulation is used to create Triangulated Irregular Networks (TINs), which model landscapes by connecting elevation points into a mesh.
Watershed Analysis: Helps analyze water flow and drainage patterns.
Computer Graphics
Mesh Generation: Triangles are the fundamental building blocks for 3D modeling and rendering.
Collision Detection: Used in simulations to detect interactions between objects.
Telecommunications
Wireless Network Optimization: Helps optimize the placement of cell towers and the connections between them.
Voronoi-based Coverage Analysis: Delaunay edges represent backhaul connections between towers.
Robotics and Pathfinding
Motion Planning: Robots use triangulated graphs to navigate efficiently while avoiding obstacles.
Terrain Navigation: Triangulation simplifies understanding of the environment for autonomous vehicles.
Engineering and Simulation
Finite Element Analysis (FEA): Generates triangular meshes for simulating physical systems, such as stress distribution in materials.
Fluid Dynamics: Simulates the flow of fluids over surfaces.
Environmental Science
Flood Modeling: Simulates how water flows across landscapes.
Resource Management: Models the distribution of natural resources like water or minerals.
A Practical Example
To illustrate the concept, let’s consider a set of points representing small towns scattered across a region. Using
Delaunay triangulation:
The towns (points) are connected with lines (edges) to form a network.
These edges represent potential road connections, ensuring the shortest and most efficient routes between towns.
By avoiding sharp angles, this network is both practical and cost-effective for infrastructure planning.
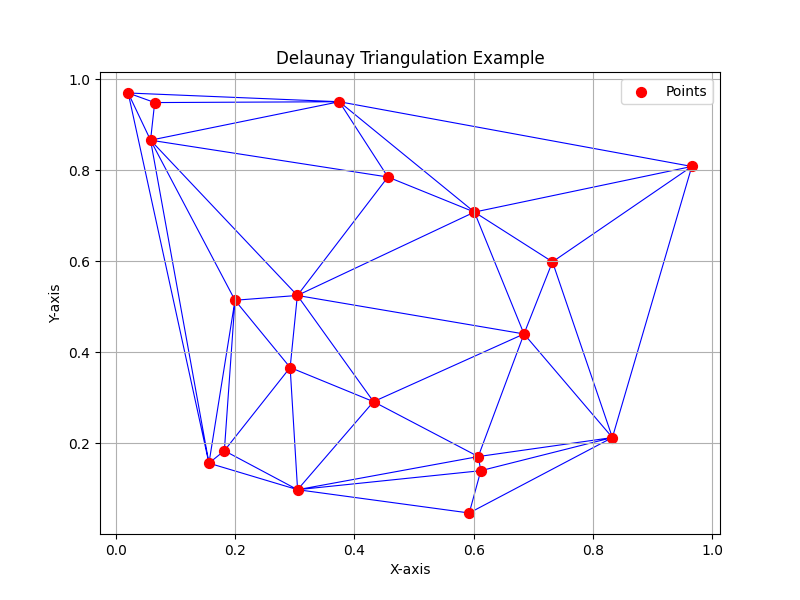
Here’s a Python script that demonstrates this idea:
importnumpyasnpimportmatplotlib.pyplotaspltfromscipy.spatialimportDelaunay# Generate random points in 2D space
np.random.seed(42)# For reproducibility
points=np.random.rand(20,2)# 20 points in 2D
# Perform Delaunay triangulation
tri=Delaunay(points)# Plot the points and the triangulation
plt.figure(figsize=(8,6))plt.triplot(points[:,0],points[:,1],tri.simplices,color='blue',linewidth=0.8)plt.scatter(points[:,0],points[:,1],color='red',s=50,label='Points')plt.title("Delaunay Triangulation Example")plt.xlabel("X-axis")plt.ylabel("Y-axis")plt.legend()plt.grid(True)plt.show()
The following is the output from this program.
Note how the paths between the points are the most optimal for connecting the towns efficiently. The triangulation
avoids unnecessary overlaps or excessively sharp angles, ensuring practicality and simplicity in the network design.
Limitations and Challenges
While Delaunay triangulation is powerful, it has its challenges:
Degenerate Cases: Points that are collinear or on the same circle can cause issues.
Scalability: Large datasets may require optimized algorithms to compute triangulations efficiently.
Extensions to Higher Dimensions: In 3D or higher, the algorithm becomes more complex and computationally expensive.
Conclusion
Delaunay triangulation is a cornerstone of computational geometry, offering an elegant way to structure and connect
scattered points. Its versatility makes it applicable across diverse domains, from GIS to robotics and environmental
science. Whether you’re modeling terrains, optimizing networks, or simulating physical systems, Delaunay triangulation
is an indispensable tool for solving real-world problems.