As I’ve been following along in Learn You a Haskell for Great Good, I’ve been coming across some really interesting material around the type system. In today’s post, I want to walk through the Tree data type that they define in this book for the section on recursive data structures.
What it is?
A recursive data structure is a type that has itself as a type amongst its fields. Pretty wild idea, but really useful for situations of Child -> Parent, Tree -> Leaf, etc. In today’s example we’re going to be using the Tree structure which looks like this.
This data type reads as, a Tree can either be an EmptyTree or it can have two nodes (that are also trees). You can start to see that this would be a best-fit as a binary search tree. Using an instance of Functor, we can give the the Tree data type recursively iterative properties through fmap.
Getting data into the tree is done cleverly (or so I think) with some basic pattern matching. I think it’s done cleverly because it reads so well/humanly (perhaps I’m easily pleased).
Inserting an EmptyTree node will result in a node with an EmptyTree either side. Inserting data for key that exists will overwrite the existing data. Inserting a lesser key (lesser according to Ord) will put the node on the left, greater onto the right. Actually building a tree can be as simple as the following.
3 is at the trunk with no left-hand-side. 3’s right hand side has a 7 with 5 for its left hand side and no right hand sides (for 5 or 7). Reading the dump out from ghci is going to be better for your understanding than trying to read my English describing the tree’s structure. The important part that I wanted to illustrate really was the use of fmap here. We map the function (*1) so that none of the values in our source array change. We apply treeInsert in a fold-right starting with EmptyTree across the source array [5,7,3].
I wanted to do a quick write up on the Boost library’sSmart Pointers and when they should and shouldn’t be used. I’d hope to use this post in future (if the knowledge doesn’t stick in my head) as a rough guide when finding the right tool for the job. For the uninitiated, I strongly advise that you go through the smart pointer documentation on the Boost website as it’s a real eye-opener as to just how hands-off you can now be with dynamic memory allocation in C++ (these days).
Why use Smart Pointers?
Smart pointers will help you manage the lifetime of your objects. It will force you to think about the ownership of these pointers and who’s currently “in-charge” in some cases. They will allow you to think in terms of observation of objects so that you don’t disturb the ownership of a resource and they just generally make your code cleaner, easier to maintain and read.
How can I start using Smart Pointers?
Get Boost! That’s going to be the best way. Dive right in, take a look at samples, set things up, blow them up - be a scientist about it! Anyway, enough of this! On to the pointers.
scoped_ptr is all about ensuring that the pointer that you’re working with is the ultimate owner of the resource that it points to. There’s no facility within this pointer type to transfer the ownership of the inner resource elsewhere. With all of this in mind, scoped_ptr ensures that the resource that is under ownership will be destroyed properly once the pointer has dropped out of scope. scoped_ptr is a very lightweight resource. It’s by no means going to harm the performance or size of your application. scoped_array will perform the same service as scoped_ptr does, it’s just that scoped_array will work on array types (as the name suggests).
shared_ptr is all about reference counting. They will internally manage the reference count that they have and govern the managed resource’s lifespan based on this. The clear advantage that they have over the scoped_ptr and scoped_array counterparts is their ability to be shared between multiple owner so that those owners can maintain their interest in the object by “hanging around”. The true power of this class of pointer is when you don’t know when to delete the underlying resource. As long as someone is referencing you, you’ll stay alive. shared_array will perform the same service as shared_ptr does, it’s just that shared_array will work on array types (deja vu anyone?)
The intrusive_ptr is another reference counting pointer only is allows you to provide your own mechanism for performing the reference counting. This means if you have an existing codebase that does all of this work for you, all you need to do is provide it to an intrusive_ptr. intrusive_ptr also allows for native usage of the this keyword.
This is just a short tutorial on using the MapReduce operation from within the MongoDB environment.
What is it and how does it work?
MapReduce is a database operation. Its intended for performing higher-level (or more complex) aggregation tasks across huge data stores. You supply it with two functions, a map function and a reduce function and it will supply you with the aggregated result. As it’s defined from the MongoDB documentation, the operation takes the following form:
You can immediately see the first two parameters to this operation as the map function and the reduce function. The remaining parameter is focused on the delivery of the result back to you.
The Map Function
The map function is responsible for defining the data that you want to work with. For instance, if you’re interested in accumulating the sum of all products sold by their category you will want to return both the amount sold per line item as well as the product’s category.
Note the use of the emit function. Its use tells the MapReduce operation that the key for this process will be category and the value will be price. The value part of the emit function can also take form of a javascript object itself should you need to perform multiple aggregations across the same data set.
This particular map function gives us a count of 1 per result that comes out so we would be able to not only sum the price but find out how many items made up the sum as well.
The Reduce Function
The reduce function is responsible for performing the aggregation on the data emitted by the map function. It is passed the key-values emitted by the map function as parameters to it. Performing the reduce function to get the sum of all prices and the number of items making up the sum total would look like this.
varreduceFunction=function(key,values){outValue={total:0,count:0};// aggregate all of the values for this keyfor(vari=0;i<values.length;i++){outValue.total+=values[i].price;outValue.count+=values[i].count;}returnoutValue;};
All of the “magic” happens via-javascript. Pretty easy really.
Getting a result
Putting your map and reduce function together for the operation ends up looking like this (for a simple scenario).
This will get the process underway against the database. Once it’s finished doing the hard-yards, then you can start basing your aggregation reports off of the “res” variable that we built just above by doing the following.
db[res.result].find();
This is only a “scratch-the-surface” - “know enough to be dangerous” type write-up. MapReduce is a complex and powerful tool that you should be reading the official documentation about if you want to achieve ninja-like status.
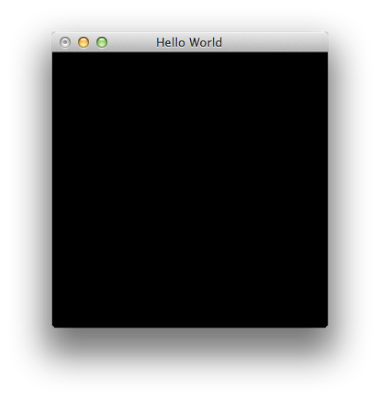
We’re into some of the real good stuff here. One of my favourite topics in computer programming is graphics (2d and 3d). In this post, I get to make a start on some fun stuff and learn some Haskell at the same time. We’re going to open an OpenGL window, clear the back buffer out and flip.
The code
importGraphics.Rendering.OpenGLimportGraphics.UI.GLUTmain::IO()main=do-- initialize openGL (progname,_)<-getArgsAndInitialize-- open up the application window createWindow"Hello World"-- set the render proc and run the main loop displayCallback$=displaymainLoopdisplay::IO()display=do-- clear the buffer and flip clear[ColorBuffer]flush
Ok, ok, fair enough - this is almost a direct-rip from the [Haskell Wiki](http://www.haskell.org/haskellwiki/OpenGLTutorial1_, I’m not claiming it as my code. It’s more of a bookmark as a good foot-hold in the OpenGL-Haskell marriage!
Compilation
Getting your application compiled is cake, just make sure you specify GLUT as a package.
As a bit of a bookmark to myself, I wanted to make mention of a study group that an old colleague had brought to my attention.
The wiki that has been put up for this project has been a great source of home-work as I’ve gone through the book. I haven’t yet made it to the end of the book but am working on it. It’s been important for me to have some home work to do on this topic as I don’t write Haskell professionally. Without something flexing my Haskell muscles, the knowledge tends to go on holiday rather quickly.
The learn repository has all of the source code and documents for the course.